

当数据遭遇“爆仓”,你可以把它们都倒进“湖”里!
作者:刘沙 | 来源:计算机世界
2020-03-30
实施数据湖的组织比同类公司在有机收入增长方面高出 9%。
新冠肺炎疫情的蔓延让我们再次体会到了大数据的重要性:通过疫情电信大数据分析模型,可以统计全国人员流动的情况,从而帮助政府预判疫情传播趋势;通过密切接触者分析模型,可以判断可能产生的新高风险区域;通过智慧交通大数据,可以监测到热点城市的交通枢纽以及城市内部出行人流的强度,判断复产复工率……
事实上,不只是对于政府,对于企业来说,数据也是极其重要的战略资产。在AWS首席云计算企业战略顾问张侠博士看来,企业里的数据流,就像人体里的血液流一样重要。

早在2017年,《经济学人》杂志就曾发出过"世界最有价值的资源不再是石油,而是数据"的论断。而在近两年所有IT人言必称的"数字化转型"中,一个很重要的内容就是把企业的数据资产用好。
从数据仓库到数据湖
其实,数据的价值在于从中提取出真正有用的信息,然后把这些信息转变成知识,再指导我们的行动。这些都离不开数据的存储、计算、分析等过程。
而在这个移动互联网时代,数据已呈现出指数级生长,数据的来源五花八门,数据的形式日益多元化,数据的使用者遍布各行各业,用来分析数据的工具也越来越多,传统的数据库已经不能应对数据的增长。
张侠解释到,传统的方法是数据库放在最下面,从ERP、CRM等业务系统中整理出数据,放在数据仓库里,然后再展示出商务智能。如今数据的来源已变成各种装置、网站、传感器和社交软件,如果还是走从数据库到数据仓库再到商务智能的老路,就会形成所谓的数据孤岛,无法满足数据的迅速增长。"这时,企业需要的是一个数据湖。"
张侠表示,数据湖不仅能解决上述的问题,还能兼容传统的数据仓库、数据分析方法,而且特别适合与机器学习这样的新技术结合起来,做更多预测性的分析。
那么,数据湖究竟是什么?
张侠解释到,数据湖是一个集中式存储数据的容器,这个容器可以存储各种各样结构化和非结构化的数据,这些数据从数据量上非常容易快速缩放,利用云计算海量存储的能力和各种查询能力,以及各种数据分析和处理的能力,可以直接对这些原始数据进行查询。在查询的过程中,还可以通过建目录和数据的转移、抽取等方式,把它们进一步归类,快速做各种各样的分析。数据湖有两个很重要的特点:一个是高可用、高持久、海量的数据,另一个是满足安全、合规、可审计的要求。
"打个比方,以前的数据流就像一条小河,我们知道这条河里大概会来多少水,我们有闸门可以处理、使用这些数据。但是到了移动互联网时代,新的海量数据爆发出来,我们很难掌握这些数据是什么性质,可能数据量会突然变得很大、很多,我们来不及整理。过去可能要花几个月、甚至半年时间才能把这些数据整理清楚,存在数据库里,再提取到数据仓库里,然后再使用它们。但现在我们只好先找一大片洼地,把所有数据像湖水一样先蓄在湖里,不过现在我们有工具可以直接查询它们。"
云上的数据湖到底什么样?
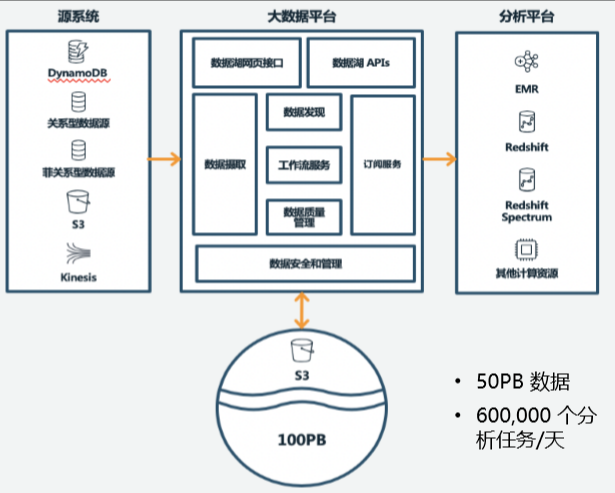
据了解,亚马逊很早就推出了有关数据湖的服务,2011年就有了数据湖的概念和一些开源应用。2016年左右,AWS推出了关键服务,开始把Amazon S3作为数据湖的核心存储。Amazon S3可以存储任何以二进位为基础的信息,包含结构化和非结构化的数据,可以把来自不同地方、不同形式的数据通过一定的方法提取出来,存储下来,做一个目录登记,存在数据湖的核心里,然后再用各种各样的分析手段把这些数据还原成数据仓库的性质,或者变成各种报表,或者变成各种预测,或者用来做机器学习的分析等等。
"从AWS的角度来讲,我们有相应的服务可以实现上述每一个功能。这些服务都是以云的方式提供的,而且非常容易上手。"张侠向记者介绍。
首先是Amazon S3,它可以存储所有类型的数据,有11个9的数据持久性,它在云上的三个可用区里存了六份,互为备份。它的后端有个叫Amazon Glacier的冷存储,把不常用的数据转存到这里,可以降低很多费用,只是再拿出来时需要多三四个小时,还有一个深度冷存储Deep Archive。此外还有一个非关系型数据库Amazon DynamoDB,存储键值类的数据,全球有大量键值配对的数据都存储在Amazon DynamoDB中。张侠补充到,"这两种是最基础的存储服务。"
Amazon RDS是云托管的关系型数据库,支持SQL Server、Oracle的数据库,开源的PostgreSQL、MySQL数据库,以及亚马逊专有的Amazon Aurora数据库。
Amazon Aurora是全方位托管的,可以兼容MySQL和PostgreSQL的纯云原生数据库。张侠强调,"这个数据库自推出以来,是AWS所有云服务里增长速度最快的,拥有大量用户。"
Amazon Redshift是云数据仓库,使用简单,可以扩展,成本是传统数据库的1/10左右。
Amazon EMR是用类似开源、Hadoop的方法来做大数据的集群分析。
Amazon Kinesis用来处理实时数据,包括四种不同类型,有的能直接处理视频的数据流,有的可以把数据直接导到关键服务,各自有不同的用法。
Amazon Athena是一种交互式查询服务,它让客户可以使用标准SQL语言、轻松分析Amazon Simple Storage Service (Amazon S3) 中的数据。由于Athena是一种无服务器服务,因此客户不需要管理基础设施,只为他们运行的查询付费。Athena可以自动扩展,并行执行查询,即便是大型数据集和复杂的查询,也能很快获得查询结果。
AWS Glue是一种全托管的数据提取、转换和加载 (ETL) 服务及元数据目录。它让客户更容易准备数据,加载数据到数据库、数据仓库和数据湖,用于数据分析。使用AWS Glue,在几分钟之内便可以准备好数据用于分析。由于AWS Glue是无服务器服务,客户在执行ETL任务时,只需要为他们所消耗的计算资源付费。
近日,Amazon Athena和AWS Glue也在由西云数据运营的AWS中国 (宁夏) 区域正式上线了。
张侠告诉记者,虽然数据湖是个好工具,但是建立安全的数据湖还是要面临一定挑战。在一般情况下,构建安全的数据湖,首先要把数据设置好,存储起来,然后把数据移动、加载到不同地方,进行清理,编写数据目录,再配置并实施安全性与合规性策略,之后在需要的时候就可以把这些数据拿出来做各种分析。
为了帮助企业用户更快的使用数据湖,AWS专门推出了AWS Lake Formation服务,让上述建立数据湖的工作可以自动化操作,让企业在短短几天内就完成数据湖的建设工作。
不可或缺的数据分析
AWS全球副总裁及大中华区执行董事张文翊表示,"AWS可扩展、可靠的云存储,加上广泛的分析服务,使客户比以往任何时候都更容易收集、存储、分析和共享数据。中国区域的客户可以从任意多的数据源传输和处理数据,整合数据到数据湖,并且可以选用多种AWS分析服务,分析所有数据。"
据介绍,AWS提供的数据分析组件包括:
数据迁移和移动工具,如AWS Database Migration Service数据库迁移服务 (DMS), AWS Snowball (雪球),AWS Storage Gateway, AWS Backup数据备份服务。
数据存储工具,如Amazon S3、Amazon Glacier、Amazon DynamoDB,以及非关系型数据库、Amazon RDS关系型数据库、Amazon Aurora纯原生的云数据库、Amazon ElastiCache云上内存式数据库,还有Amazon Neptune基于图形的数据库。
数据湖,最主要的三大元素是Amazon S3/Glacier, AWS Glue和AWS Lake Formation。
数据分析工具,如Amazon Redshift数据仓库,Amazon EMR大数据分析,AWS Glue无服务器数据分析,Amazon Athena (雅典娜)交互式分析,Amazon Elasticsearch运维分析,还有Amazon Kinesis实时数据分析。
机器学习工具,如图形可视化的Amazon QuickSight、 Amazon Polly、Amazon Transcribe、Amazon SageMaker。其中Amazon SageMaker是人工智能服务,很快会在中国推出。
张侠补充到:"在大数据分析服务的全景图中,大多数服务都已经在中国落地,目前已有很多客户在使用。"
让更多企业通过数据洞察先机
Aberdeen 的一项调查表明,通过数据成功创造商业价值的企业将胜过同行,实施数据湖的组织比同类公司在有机收入增长方面高出 9%。
目前全球范围内有大量公司都在使用AWS的数据湖和数据分析工具,无论是互联网公司,还是传统企业公司,几乎覆盖了各行各业。
张侠强调,"AWS的创新都是围绕客户需求来做的。"亚马逊自己就是云数据库的受益者。很多业内人都知道,亚马逊曾经是Oracle全球数据库最大的用户,它用了7500多个Oracle数据库,存放75PB数据。亚马逊的1000多个不同的团队,如运营、电商、市场营销、库存等等,过去都是基于Oracle的数据库。在过去一年半到两年时间里,亚马逊全方位迁出了Oracle的数据库,迁移到了自己相应的产品云数据库中。此次迁移解决了过去扩展困难、费用昂贵,需要向Oracle支持高额费用等一系列问题,减少了数据库费用成本60%,减少了数据库管理费用70%,增加的关键性能高达40%。
不仅如此,亚马逊还在企业内部建了一个专供内部使用的数据湖,这个数据湖把亚马逊的数据整合在一起,存储量从50PB长到100PB数据。通过这个数据湖,亚马逊每天可处理多达60万的分析任务,做各种各样的数据分析,从给用户的推荐、各种运营信息、库存信息、物价信息,都可以通过数据湖来实现。"这也是亚马逊的核心竞争力之一。"张侠表示。
在对数据管理极为严苛的金融行业里也不乏成功应用。
纳斯达克交易所每天要处理300-500亿条信息,构建了基于Amazon S3的数据湖以后,不仅降低了成本,把上市时间缩短为原来的1/3,还可以选择无限制增加存储的数据量,在其数据湖中支持数十年的纳秒级消息数据。
同样是属于金融行业的美国金融监管机构FINRA每天要对超过1500亿个事件、20PB的数据运行复杂的监视查询,以检测和分析非法的市场活动。FINRA把大数据应用迁移到亚马逊的数据湖进行提取和处理后,系统提高了敏捷性和速度,每年可节省1000-2000万美元的成本。
中国也有不少企业在使用亚马逊的数据产品,如Club Factory。这是2016年由嘉云数据在杭州创建的一家时尚、美容和生活领域的电子商务商店,它整合了上百万个供应商,上游有数千万个SKU,下游覆盖27个国家和地区,积累了1亿多全球用户群。Club Factory每天要处理15亿条各种行为的分析,支撑80多位工程师的数据分析和算法需求,支撑180个活跃数据的分析调度任务,同步4000多个各种数据到Amazon Redshift,支撑的数据总量达600TB。基于AWS数据湖架构建设数据化智能化的电商平台,Club Factory实现了业务任意规模的扩展,以及人工智能+商品、人工智能+消费者、人工智能+供应链的全方位技术创新,有效节省了存储成本,降低了ETL和操作层面的复杂度,以及额外的工作量。
张侠指出,基本上各行各业、各种规模的企业都可以采用数据湖为自己搭建数据应用平台。我们可以看到,很多企业用户都通过使用数据湖和数据分析,为企业的创新和发展洞察先机。随着人工智能、物联网、5G、边缘计算等技术普及,数据湖的应用和作用性也将会越来越强。
事实上,不只是对于政府,对于企业来说,数据也是极其重要的战略资产。在AWS首席云计算企业战略顾问张侠博士看来,企业里的数据流,就像人体里的血液流一样重要。
AWS首席云计算企业战略顾问 张侠博士
早在2017年,《经济学人》杂志就曾发出过"世界最有价值的资源不再是石油,而是数据"的论断。而在近两年所有IT人言必称的"数字化转型"中,一个很重要的内容就是把企业的数据资产用好。
从数据仓库到数据湖
其实,数据的价值在于从中提取出真正有用的信息,然后把这些信息转变成知识,再指导我们的行动。这些都离不开数据的存储、计算、分析等过程。
而在这个移动互联网时代,数据已呈现出指数级生长,数据的来源五花八门,数据的形式日益多元化,数据的使用者遍布各行各业,用来分析数据的工具也越来越多,传统的数据库已经不能应对数据的增长。
张侠解释到,传统的方法是数据库放在最下面,从ERP、CRM等业务系统中整理出数据,放在数据仓库里,然后再展示出商务智能。如今数据的来源已变成各种装置、网站、传感器和社交软件,如果还是走从数据库到数据仓库再到商务智能的老路,就会形成所谓的数据孤岛,无法满足数据的迅速增长。"这时,企业需要的是一个数据湖。"
张侠表示,数据湖不仅能解决上述的问题,还能兼容传统的数据仓库、数据分析方法,而且特别适合与机器学习这样的新技术结合起来,做更多预测性的分析。
那么,数据湖究竟是什么?
张侠解释到,数据湖是一个集中式存储数据的容器,这个容器可以存储各种各样结构化和非结构化的数据,这些数据从数据量上非常容易快速缩放,利用云计算海量存储的能力和各种查询能力,以及各种数据分析和处理的能力,可以直接对这些原始数据进行查询。在查询的过程中,还可以通过建目录和数据的转移、抽取等方式,把它们进一步归类,快速做各种各样的分析。数据湖有两个很重要的特点:一个是高可用、高持久、海量的数据,另一个是满足安全、合规、可审计的要求。
云上的数据湖到底什么样?
据了解,亚马逊很早就推出了有关数据湖的服务,2011年就有了数据湖的概念和一些开源应用。2016年左右,AWS推出了关键服务,开始把Amazon S3作为数据湖的核心存储。Amazon S3可以存储任何以二进位为基础的信息,包含结构化和非结构化的数据,可以把来自不同地方、不同形式的数据通过一定的方法提取出来,存储下来,做一个目录登记,存在数据湖的核心里,然后再用各种各样的分析手段把这些数据还原成数据仓库的性质,或者变成各种报表,或者变成各种预测,或者用来做机器学习的分析等等。
"从AWS的角度来讲,我们有相应的服务可以实现上述每一个功能。这些服务都是以云的方式提供的,而且非常容易上手。"张侠向记者介绍。
首先是Amazon S3,它可以存储所有类型的数据,有11个9的数据持久性,它在云上的三个可用区里存了六份,互为备份。它的后端有个叫Amazon Glacier的冷存储,把不常用的数据转存到这里,可以降低很多费用,只是再拿出来时需要多三四个小时,还有一个深度冷存储Deep Archive。此外还有一个非关系型数据库Amazon DynamoDB,存储键值类的数据,全球有大量键值配对的数据都存储在Amazon DynamoDB中。张侠补充到,"这两种是最基础的存储服务。"
Amazon RDS是云托管的关系型数据库,支持SQL Server、Oracle的数据库,开源的PostgreSQL、MySQL数据库,以及亚马逊专有的Amazon Aurora数据库。
Amazon Aurora是全方位托管的,可以兼容MySQL和PostgreSQL的纯云原生数据库。张侠强调,"这个数据库自推出以来,是AWS所有云服务里增长速度最快的,拥有大量用户。"
Amazon Redshift是云数据仓库,使用简单,可以扩展,成本是传统数据库的1/10左右。
Amazon EMR是用类似开源、Hadoop的方法来做大数据的集群分析。
Amazon Kinesis用来处理实时数据,包括四种不同类型,有的能直接处理视频的数据流,有的可以把数据直接导到关键服务,各自有不同的用法。
Amazon Athena是一种交互式查询服务,它让客户可以使用标准SQL语言、轻松分析Amazon Simple Storage Service (Amazon S3) 中的数据。由于Athena是一种无服务器服务,因此客户不需要管理基础设施,只为他们运行的查询付费。Athena可以自动扩展,并行执行查询,即便是大型数据集和复杂的查询,也能很快获得查询结果。
AWS Glue是一种全托管的数据提取、转换和加载 (ETL) 服务及元数据目录。它让客户更容易准备数据,加载数据到数据库、数据仓库和数据湖,用于数据分析。使用AWS Glue,在几分钟之内便可以准备好数据用于分析。由于AWS Glue是无服务器服务,客户在执行ETL任务时,只需要为他们所消耗的计算资源付费。
近日,Amazon Athena和AWS Glue也在由西云数据运营的AWS中国 (宁夏) 区域正式上线了。
张侠告诉记者,虽然数据湖是个好工具,但是建立安全的数据湖还是要面临一定挑战。在一般情况下,构建安全的数据湖,首先要把数据设置好,存储起来,然后把数据移动、加载到不同地方,进行清理,编写数据目录,再配置并实施安全性与合规性策略,之后在需要的时候就可以把这些数据拿出来做各种分析。
为了帮助企业用户更快的使用数据湖,AWS专门推出了AWS Lake Formation服务,让上述建立数据湖的工作可以自动化操作,让企业在短短几天内就完成数据湖的建设工作。
不可或缺的数据分析
AWS全球副总裁及大中华区执行董事张文翊表示,"AWS可扩展、可靠的云存储,加上广泛的分析服务,使客户比以往任何时候都更容易收集、存储、分析和共享数据。中国区域的客户可以从任意多的数据源传输和处理数据,整合数据到数据湖,并且可以选用多种AWS分析服务,分析所有数据。"
据介绍,AWS提供的数据分析组件包括:
数据迁移和移动工具,如AWS Database Migration Service数据库迁移服务 (DMS), AWS Snowball (雪球),AWS Storage Gateway, AWS Backup数据备份服务。
数据存储工具,如Amazon S3、Amazon Glacier、Amazon DynamoDB,以及非关系型数据库、Amazon RDS关系型数据库、Amazon Aurora纯原生的云数据库、Amazon ElastiCache云上内存式数据库,还有Amazon Neptune基于图形的数据库。
数据湖,最主要的三大元素是Amazon S3/Glacier, AWS Glue和AWS Lake Formation。
数据分析工具,如Amazon Redshift数据仓库,Amazon EMR大数据分析,AWS Glue无服务器数据分析,Amazon Athena (雅典娜)交互式分析,Amazon Elasticsearch运维分析,还有Amazon Kinesis实时数据分析。
机器学习工具,如图形可视化的Amazon QuickSight、 Amazon Polly、Amazon Transcribe、Amazon SageMaker。其中Amazon SageMaker是人工智能服务,很快会在中国推出。
张侠补充到:"在大数据分析服务的全景图中,大多数服务都已经在中国落地,目前已有很多客户在使用。"
让更多企业通过数据洞察先机
Aberdeen 的一项调查表明,通过数据成功创造商业价值的企业将胜过同行,实施数据湖的组织比同类公司在有机收入增长方面高出 9%。
目前全球范围内有大量公司都在使用AWS的数据湖和数据分析工具,无论是互联网公司,还是传统企业公司,几乎覆盖了各行各业。
张侠强调,"AWS的创新都是围绕客户需求来做的。"亚马逊自己就是云数据库的受益者。很多业内人都知道,亚马逊曾经是Oracle全球数据库最大的用户,它用了7500多个Oracle数据库,存放75PB数据。亚马逊的1000多个不同的团队,如运营、电商、市场营销、库存等等,过去都是基于Oracle的数据库。在过去一年半到两年时间里,亚马逊全方位迁出了Oracle的数据库,迁移到了自己相应的产品云数据库中。此次迁移解决了过去扩展困难、费用昂贵,需要向Oracle支持高额费用等一系列问题,减少了数据库费用成本60%,减少了数据库管理费用70%,增加的关键性能高达40%。
不仅如此,亚马逊还在企业内部建了一个专供内部使用的数据湖,这个数据湖把亚马逊的数据整合在一起,存储量从50PB长到100PB数据。通过这个数据湖,亚马逊每天可处理多达60万的分析任务,做各种各样的数据分析,从给用户的推荐、各种运营信息、库存信息、物价信息,都可以通过数据湖来实现。"这也是亚马逊的核心竞争力之一。"张侠表示。
在对数据管理极为严苛的金融行业里也不乏成功应用。
纳斯达克交易所每天要处理300-500亿条信息,构建了基于Amazon S3的数据湖以后,不仅降低了成本,把上市时间缩短为原来的1/3,还可以选择无限制增加存储的数据量,在其数据湖中支持数十年的纳秒级消息数据。
同样是属于金融行业的美国金融监管机构FINRA每天要对超过1500亿个事件、20PB的数据运行复杂的监视查询,以检测和分析非法的市场活动。FINRA把大数据应用迁移到亚马逊的数据湖进行提取和处理后,系统提高了敏捷性和速度,每年可节省1000-2000万美元的成本。
中国也有不少企业在使用亚马逊的数据产品,如Club Factory。这是2016年由嘉云数据在杭州创建的一家时尚、美容和生活领域的电子商务商店,它整合了上百万个供应商,上游有数千万个SKU,下游覆盖27个国家和地区,积累了1亿多全球用户群。Club Factory每天要处理15亿条各种行为的分析,支撑80多位工程师的数据分析和算法需求,支撑180个活跃数据的分析调度任务,同步4000多个各种数据到Amazon Redshift,支撑的数据总量达600TB。基于AWS数据湖架构建设数据化智能化的电商平台,Club Factory实现了业务任意规模的扩展,以及人工智能+商品、人工智能+消费者、人工智能+供应链的全方位技术创新,有效节省了存储成本,降低了ETL和操作层面的复杂度,以及额外的工作量。
张侠指出,基本上各行各业、各种规模的企业都可以采用数据湖为自己搭建数据应用平台。我们可以看到,很多企业用户都通过使用数据湖和数据分析,为企业的创新和发展洞察先机。随着人工智能、物联网、5G、边缘计算等技术普及,数据湖的应用和作用性也将会越来越强。
责任编辑:刘沙




