

基于金山云的Hadoop大数据平台
作者:杨敏强 | 来源:金山云
2018-06-12
本文首先介绍基于Hadoop大数据平台的逻辑架构,然后阐述基于金山云的两种部署模式,最后介绍基于Hadoop大数据平台的三种应用场景和软件架构。
1 引言
当前,数据驱动业务是推动企业业务创新,实现业务持续增长的源动力。基于Hadoop HDFS和YARN的大规模分布式存储和计算使得企业能在合理投资的前提下,实现对结构化数据和非结构化数据的离线分析和实时分析。而云计算按使用付费和弹性的特性使得企业大数据平台项目可以在更少前期投资的情况下快速启动,缩短投资回报周期,加速企业实现数据驱动业务转型。
金山云作为公有云服务提供商,为客户提供多种大数据分析平台部署模式。客户可以使用开箱即用的托管Hadoop(Kingsoft MapReduce,简称KMR)PaaS服务快速搭建大数据平台,也可以在云物理主机(Elastic Physical Cloud,简称EPC)和云服务器(Kingsoft Elastic Compute,简称KEC)两种IaaS服务上灵活搭建特殊需求的大数据平台。
本文首先介绍基于Hadoop大数据平台的逻辑架构,然后阐述基于金山云的两种部署模式,最后介绍基于Hadoop大数据平台的三种应用场景和软件架构。
2 金山云Hadoop大数据平台逻辑架构
2.1 大数据平台功能组件模型
基于金山云自身大数据实践和大数据开源软件成熟程度,建议企业采用如下大数据组件搭建大数据平台,该大数据平台充分考虑结构化和非结构化数据存储,以及实时和非实时数据分析,为业务分析人员和数据科学家提供可视化操作界面,通过大数据平台监控和管理自动化降低平台运维工作量。
此外,基于金山云搭建大数据平台,可集成金山云对象存储服务KS3(Kingsoft Standard Storage Service),实现历史数据归档存储,降低大数据存储成本。
2.2 大数据平台逻辑部署模型
生产环境中的大数据平台需要有高可用性和伸缩性,因此至少需要五台服务器。其中主节点(Master Node)和备节点(Secondary Node)主要提供HDFS, YARN, Hive和 HBase管理服务以及高可用,而其余三台核心节点(Core Node)主要提供数据存储和计算服务,以及ZooKeeper和Kafka服务。下表汇总每一个大数据组件在不同节点上所部署的服务。

说明:1、YARN App Timeline Server: jps显示是ApplicationHistoryServer;2、MapReduce 2 History Server: jps显示是JobHistoryServer;3、Spark History Server: jps显示是 HistroyServer。
上述大数据组件的客户端(比如hadoop客户端和Hive客户端等)、以及Tez和Pig可部署在任意节点上。此外,Ambari, Hive, Oozie和Hue需要关系数据库服务(比如MySQL)提供一个数据库来存储数据,该关系数据库服务可部署在一台独立服务器上。
当需要对集群扩容时,只需增加核心节点。新增节点上必须安装Ambari Metrics Monitor和Agent,但无须安装ZooKeeper服务,其他服务根据需要进行选择安装。
3 金山云Hadoop大数据分析平台部署模式
金山云以强大、安全、稳定的计算、存储和网络为依托,为客户提供托管Hadoop部署模式和基于IaaS的部署模式,从而满足不同类型客户需求。无论采取何种部署模式,整个大数据平台将通过VPC和子网ACL(访问控制列表)隔离大数据平台和其他业务系统。
3.1 托管Hadoop模式
托管Hadoop是金山云提供的大数据PaaS服务,可集成金山云的对象存储服务。用户可以通过金山云控制台在1小时内创建集群,并在集群运行过程中增加核心节点和客户端节点。下图是针对一个已创建的Hadoop集群增加核心节点和客户端节点(客户端节点主要安装大数据组件的客户端软件,比如Hive客户端)。

调整Hadoop集群配置
金山云控制台集成管理Hadoop集群的Ambari控制和集群告警功能。用户可以自定义集群告警策略,并在金山云控制台中显示Hadoop集群告警信息或者以短信和邮件发送告警提示。而且,整个大数据平台所需的关系数据库可采用金山云提供的关系型数据库服务KRDS(Kingsoft Relational Database Service)。 KRDS是一种即开即用、稳定可靠、可弹性伸缩的在线数据库服务,具有多重安全防护措施和完善的性能监控体系,提供专业的数据库备份、恢复及优化方案,从而提高整个大数据平台的可用性,并降低自己安装和维护MySQL数据库工作量。
3.2 基于IaaS的部署模式
金山云IaaS提供基于虚拟化技术的云服务器和独占的云物理主机,云服务器和云物理主机可以纳入同一个私有网络(Virtual Private Cloud,简称VPC),利用服务器安全组和子网ACL等安全机制提高服务器网络安全性。考虑到生产环境下大数据平台的性能、存储容量、伸缩性等因素,可用金山云物理主机和云服务器灵活搭建企业大数据平台,部署建议如下表:
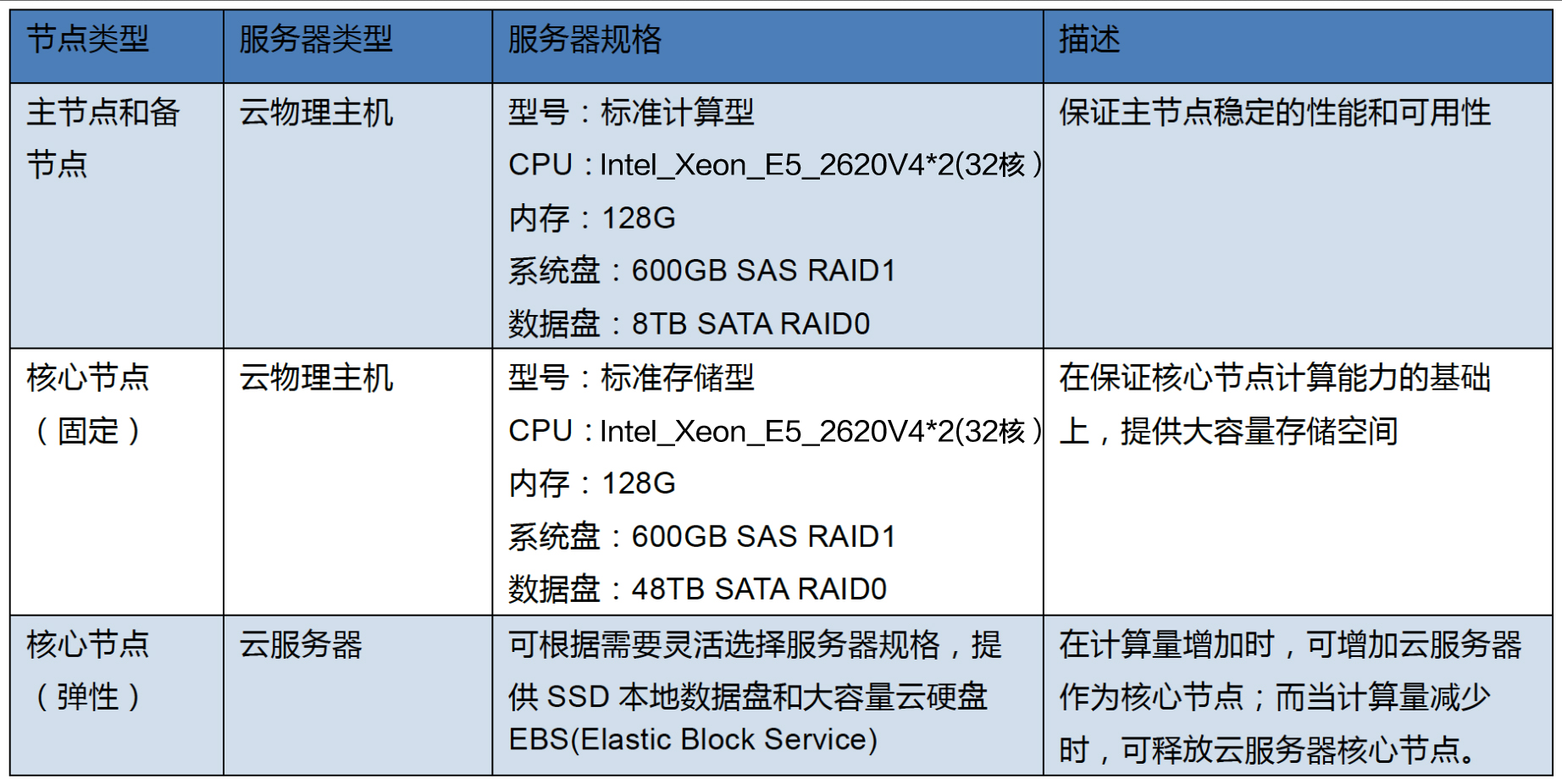
在计算量增加时,可增加云服务器作为核心节点;而当计算量减少时,可释放云服务器核心节点。
如果用户处于大数据平台的早期研究阶段,可以全用云服务器搭建大数据平台,降低大数据平台前期投入,在大数据平台真正投产后可以平滑扩展到云物理主机。
针对用户在金山云IaaS上搭建大数据平台的需求,金山云专业的实施服务团队基于开发托管Hadoop大数据平台PaaS服务的经验,向用户提供专业的大数据平台搭建和运维服务,帮助用户快速搭建和运维高可用、弹性的大数据平台。
4 金山云Hadoop大数据分析平台使用场景
如果没有应用场景,Hadoop大数据平台自身没有任何价值。虽然不同到企业的大数据应用场景各有不同,但通常可以归纳离线日志分析、实时异常检测和企业数据仓库三类。下面分别介绍基于Hadoop平台如何实现这三类场景以及软件架构。
4.1 离线日志分析
离线日志分析通常是指分析用户浏览网站而产生的日志数据,其目的是发现有价值的用户访问行为信息,以数据为依据进行客观决策。这些有价值的用户行为信息包括用户的地理分布情况,采用什么设备和操作系统访问网站,在客户转化(比如购物、注册等)前的浏览路径等。利用这些信息可以帮助分析各种营销渠道(比如直接访问,社交媒体、付费广告)推广的投资回报,并通过关联现有关系数据库(比如客户关系管理系统)中的数据进行进一步有价值的分析,比如用户访问网站并购物的百分比。日志分析技术除了应用在网站日志外,还适用于对任何机器产生的数据进行批量处理的场景,这些场景包括分析广告点击数据、服务器日志、网络日志和电信通话日志等。
整个大数据日志分析应用的架构设计应满足如下需求: 1、尽量减少对现有应用的影响,包括无需对应用进行修改,尽量减少安装额外软件。
2、避免大数据日志分析应用对整个大数据平台的产生性能影响和安全隐患,因为该大数据平台还需要支撑其它大数据应用。
3、数据分析人员通过负载均衡器访问大数据分析平台,减少大数据平台受到外网攻击。
基于上述原则,引入大数据接入子网,该子网中部署Flume Collector Agent,该Agent通过Hadoop Client向HDFS中注入日志数据,在日志采集服务器上只需安装Flume Client Agent,无需知道HDFS的接入信息(比如地址和访问账户信息等),同时通过多个Flume Collector Agent实现高可用和分流,避免在高峰访问流量时对HDFS造成大的性能影响。
详细实现流程如下:
1、首先创建Hive表并关联到特定HDFS文件目录,包括原始日志信息表和处理后的日志信息表。
2、采集服务器上的Flume Client Agent会自动扫描日志目录,当有日志文件关闭时(也就是形成日志历史文件)即处理该日志文件(比如加上时间戳,日志服务器IP地址等),并发送给Flume Collector Agent。
3、Flume Collecor Agent接收到日志信息后写入到HDFS的原始日志目录,如果日志信息太大,可按日志日期进行分区管理。如果分区后日志文件太小(比如小于HDFS的单个存储块大小,缺省64M),则应该合并分区,避免小文件太多造成HDFS性能下降。
4、每天晚上定时运行Oozie工作流,该工作流将实现如下工作:
a. 执行Pig脚本过滤掉重复的日志数据。
b. 执行Spark程序在日志数据中加入会话信息,加入会话信息的规则是在同一IP地址不超过30分钟的两次访问属于一个会话并在日志信息前面加上唯一的会话ID。
5、日志分析人员通过Hue提供的浏览器页面运行已经定制好的查询得到日志分析数据。
4.2 实时异常检测
实时异常检测是指通过发现异常行为和正常行为之间的差异,并及时(比如在几分钟内)采取相应的行动。实时异常检测的一个应用场景是发现异常信用卡交易。比如,一次信用卡交易的金额远大于用户每天的正常交易额,或者本次信用卡交易产生的地理位置不属于该信用卡交易发生的最近20个地方,或者发现通过网上银行发生的本次信用卡交易的IP地址和以前访问的20个不同,均可把该交易标识为异常交易,并采取响应的动作,比如通知客服人员通过电话和信用卡用户进行交易确认,避免信用卡用户或者银行损失。实时异常检测除了用于检测金融欺诈行为外,还可以用于电商网站实时推荐等场景。
以银行信用卡异常检测为例,整个软件架构应满足如下需求:
1、能根据信用卡画像信息(比如信用卡固定信息、累计交易信息,近20次交易历史记录等)和异常检测规则,快速标识异常交易事件。
2、能根据不断产生的信用卡交易事件实时更新信用卡画像信息。
3、能对大量交易日志进行事后分析,不断完善用户画像信息和异常检测规则模型。
基于上述模型,设计如下信用卡交易异常检测软件架构。
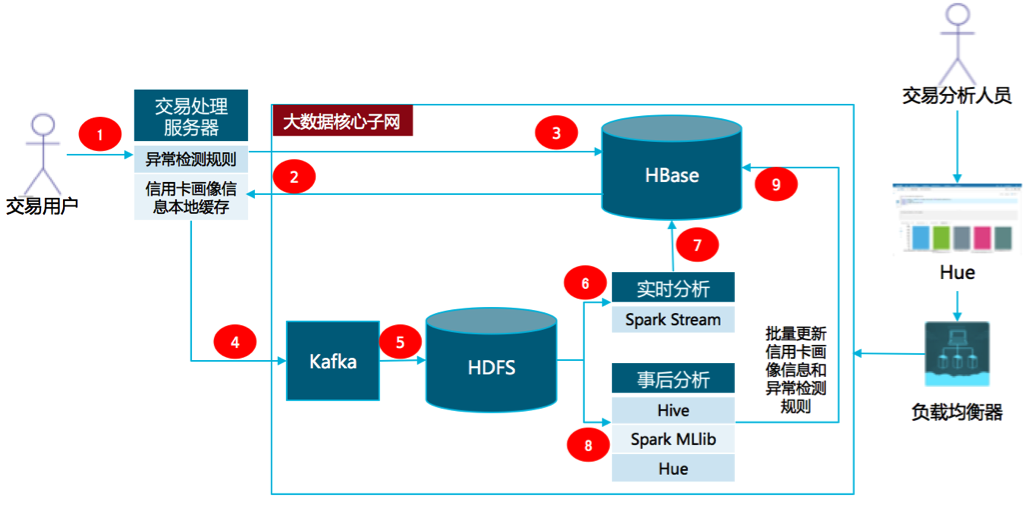
大数据实时异常检测软件架构图
在上述架构中,采用HBase来存储上亿条信用卡画像信息,并提供快速查询和更新功能。而通过Kafka,可以把交易事件数据及时注入到HDFS,并通过Spark Steam进行实时分析并更新存储在HBase中的信用卡画像信息。整个实现流程如下:
1、用户信用卡刷卡交易信息发送给交易处理服务器。
2、交易处理服务器会首先从本地缓存中获得信用卡画像信息,或则从HBase中获得最新的用户画像信息。
3、在交易服务器本次对交易异常检测进行判断,并把结果实时更新到HBase。
4、交易事件信息发送到Kafka消息队列。
5、Kafka Topic处理程序会实时把交易事件信息发送到HDFS。
6、基于Spark Stream的实时处理程序会从HDFS中获得交易事件信息并进行关联分析。
7、基于Spakr Steam的实时处理程序把分析结果写入HBase。
8、数据分析人员通过浏览器访问Hue,运行Hive分析脚本或者运行基于Spark机器学习库MLlib的机器学习程序,对交易数据进行分析,并批量更新HBase中的数据。
4.3 企业数据仓库
在大数据时代,企业通常会在Hadoop HDFS存储非结构化数据,而在关系数据中存储结构化数据,这就要求对这两类数据进行整合,并通过各种分析手段发掘数据价值。采用传统的数据仓库技术来整合Hadoop HDFS中的数据,完成数据的整个ETL(抽取Etract、转换Tansform和加载Load)过程,会极大增加数据仓库资金投入成本,也很难完成PB级的非结构化数据处理。因此,基于Hadoop构建企业数据仓库,在Hadoop中完成结构化数据和非结构化数据的ETL过程,利用Hive、Hue等工具进行全面分析,或者在数据抽取和转换形成后,把经过转换的数据导入到企业现有数据仓库,利用各种商业智能(Business Intelligence,简称BI)工具进行数据分析。基于这个思路,采用Hadoop建设数据仓库系统的设计架构如下图:

基于Hadoop的企业数据仓库架构
基于上述架构的企业数据仓库系统的实现逻辑如下:
1、利用Sqoop从关系数据库中抽取结构化数据导入到HDFS。
2、利用Flume或者Kafka把非结构化数据导入到HDFS。
3、优化HDFS中的数据存储模式,包括优化数据模型和文件格式。
4、利用Hive或者Spark对数据进行转换处理。
5、通过Oozie编排整个处理过程,实现ETL过程自动化。
6、利用Hue对变形后数据进行可视化分析。
7、或者通过Sqoop把变形后数据导入到现有数据仓库,利用BI工具进行分析。
5 总结
金山云经过多年公有云运营,已建立强大的IaaS基础设施并积累丰富的运营经验,并提供灵活的云上大数据平台建设方案,帮助企业快速挖掘数据价值,助力企业实现数据驱动业务快速转型。
6 参考资料
1、金山云托管Hadoop KMR服务:http://www.ksyun.com/proservice/kmr
2、金山云云物理主机 EPC服务:http://www.ksyun.com/proservice/physicalmaster
3、金山云云服务器 KEC服务:http://www.ksyun.com/proservice/cloudserver
当前,数据驱动业务是推动企业业务创新,实现业务持续增长的源动力。基于Hadoop HDFS和YARN的大规模分布式存储和计算使得企业能在合理投资的前提下,实现对结构化数据和非结构化数据的离线分析和实时分析。而云计算按使用付费和弹性的特性使得企业大数据平台项目可以在更少前期投资的情况下快速启动,缩短投资回报周期,加速企业实现数据驱动业务转型。
金山云作为公有云服务提供商,为客户提供多种大数据分析平台部署模式。客户可以使用开箱即用的托管Hadoop(Kingsoft MapReduce,简称KMR)PaaS服务快速搭建大数据平台,也可以在云物理主机(Elastic Physical Cloud,简称EPC)和云服务器(Kingsoft Elastic Compute,简称KEC)两种IaaS服务上灵活搭建特殊需求的大数据平台。
本文首先介绍基于Hadoop大数据平台的逻辑架构,然后阐述基于金山云的两种部署模式,最后介绍基于Hadoop大数据平台的三种应用场景和软件架构。
2 金山云Hadoop大数据平台逻辑架构
2.1 大数据平台功能组件模型
基于金山云自身大数据实践和大数据开源软件成熟程度,建议企业采用如下大数据组件搭建大数据平台,该大数据平台充分考虑结构化和非结构化数据存储,以及实时和非实时数据分析,为业务分析人员和数据科学家提供可视化操作界面,通过大数据平台监控和管理自动化降低平台运维工作量。
此外,基于金山云搭建大数据平台,可集成金山云对象存储服务KS3(Kingsoft Standard Storage Service),实现历史数据归档存储,降低大数据存储成本。
2.2 大数据平台逻辑部署模型
生产环境中的大数据平台需要有高可用性和伸缩性,因此至少需要五台服务器。其中主节点(Master Node)和备节点(Secondary Node)主要提供HDFS, YARN, Hive和 HBase管理服务以及高可用,而其余三台核心节点(Core Node)主要提供数据存储和计算服务,以及ZooKeeper和Kafka服务。下表汇总每一个大数据组件在不同节点上所部署的服务。
说明:1、YARN App Timeline Server: jps显示是ApplicationHistoryServer;2、MapReduce 2 History Server: jps显示是JobHistoryServer;3、Spark History Server: jps显示是 HistroyServer。
上述大数据组件的客户端(比如hadoop客户端和Hive客户端等)、以及Tez和Pig可部署在任意节点上。此外,Ambari, Hive, Oozie和Hue需要关系数据库服务(比如MySQL)提供一个数据库来存储数据,该关系数据库服务可部署在一台独立服务器上。
当需要对集群扩容时,只需增加核心节点。新增节点上必须安装Ambari Metrics Monitor和Agent,但无须安装ZooKeeper服务,其他服务根据需要进行选择安装。
3 金山云Hadoop大数据分析平台部署模式
金山云以强大、安全、稳定的计算、存储和网络为依托,为客户提供托管Hadoop部署模式和基于IaaS的部署模式,从而满足不同类型客户需求。无论采取何种部署模式,整个大数据平台将通过VPC和子网ACL(访问控制列表)隔离大数据平台和其他业务系统。
3.1 托管Hadoop模式
托管Hadoop是金山云提供的大数据PaaS服务,可集成金山云的对象存储服务。用户可以通过金山云控制台在1小时内创建集群,并在集群运行过程中增加核心节点和客户端节点。下图是针对一个已创建的Hadoop集群增加核心节点和客户端节点(客户端节点主要安装大数据组件的客户端软件,比如Hive客户端)。
调整Hadoop集群配置
金山云控制台集成管理Hadoop集群的Ambari控制和集群告警功能。用户可以自定义集群告警策略,并在金山云控制台中显示Hadoop集群告警信息或者以短信和邮件发送告警提示。而且,整个大数据平台所需的关系数据库可采用金山云提供的关系型数据库服务KRDS(Kingsoft Relational Database Service)。 KRDS是一种即开即用、稳定可靠、可弹性伸缩的在线数据库服务,具有多重安全防护措施和完善的性能监控体系,提供专业的数据库备份、恢复及优化方案,从而提高整个大数据平台的可用性,并降低自己安装和维护MySQL数据库工作量。
3.2 基于IaaS的部署模式
金山云IaaS提供基于虚拟化技术的云服务器和独占的云物理主机,云服务器和云物理主机可以纳入同一个私有网络(Virtual Private Cloud,简称VPC),利用服务器安全组和子网ACL等安全机制提高服务器网络安全性。考虑到生产环境下大数据平台的性能、存储容量、伸缩性等因素,可用金山云物理主机和云服务器灵活搭建企业大数据平台,部署建议如下表:
在计算量增加时,可增加云服务器作为核心节点;而当计算量减少时,可释放云服务器核心节点。
如果用户处于大数据平台的早期研究阶段,可以全用云服务器搭建大数据平台,降低大数据平台前期投入,在大数据平台真正投产后可以平滑扩展到云物理主机。
针对用户在金山云IaaS上搭建大数据平台的需求,金山云专业的实施服务团队基于开发托管Hadoop大数据平台PaaS服务的经验,向用户提供专业的大数据平台搭建和运维服务,帮助用户快速搭建和运维高可用、弹性的大数据平台。
4 金山云Hadoop大数据分析平台使用场景
如果没有应用场景,Hadoop大数据平台自身没有任何价值。虽然不同到企业的大数据应用场景各有不同,但通常可以归纳离线日志分析、实时异常检测和企业数据仓库三类。下面分别介绍基于Hadoop平台如何实现这三类场景以及软件架构。
4.1 离线日志分析
离线日志分析通常是指分析用户浏览网站而产生的日志数据,其目的是发现有价值的用户访问行为信息,以数据为依据进行客观决策。这些有价值的用户行为信息包括用户的地理分布情况,采用什么设备和操作系统访问网站,在客户转化(比如购物、注册等)前的浏览路径等。利用这些信息可以帮助分析各种营销渠道(比如直接访问,社交媒体、付费广告)推广的投资回报,并通过关联现有关系数据库(比如客户关系管理系统)中的数据进行进一步有价值的分析,比如用户访问网站并购物的百分比。日志分析技术除了应用在网站日志外,还适用于对任何机器产生的数据进行批量处理的场景,这些场景包括分析广告点击数据、服务器日志、网络日志和电信通话日志等。
整个大数据日志分析应用的架构设计应满足如下需求: 1、尽量减少对现有应用的影响,包括无需对应用进行修改,尽量减少安装额外软件。
2、避免大数据日志分析应用对整个大数据平台的产生性能影响和安全隐患,因为该大数据平台还需要支撑其它大数据应用。
3、数据分析人员通过负载均衡器访问大数据分析平台,减少大数据平台受到外网攻击。
基于上述原则,引入大数据接入子网,该子网中部署Flume Collector Agent,该Agent通过Hadoop Client向HDFS中注入日志数据,在日志采集服务器上只需安装Flume Client Agent,无需知道HDFS的接入信息(比如地址和访问账户信息等),同时通过多个Flume Collector Agent实现高可用和分流,避免在高峰访问流量时对HDFS造成大的性能影响。
详细实现流程如下:
1、首先创建Hive表并关联到特定HDFS文件目录,包括原始日志信息表和处理后的日志信息表。
2、采集服务器上的Flume Client Agent会自动扫描日志目录,当有日志文件关闭时(也就是形成日志历史文件)即处理该日志文件(比如加上时间戳,日志服务器IP地址等),并发送给Flume Collector Agent。
3、Flume Collecor Agent接收到日志信息后写入到HDFS的原始日志目录,如果日志信息太大,可按日志日期进行分区管理。如果分区后日志文件太小(比如小于HDFS的单个存储块大小,缺省64M),则应该合并分区,避免小文件太多造成HDFS性能下降。
4、每天晚上定时运行Oozie工作流,该工作流将实现如下工作:
a. 执行Pig脚本过滤掉重复的日志数据。
b. 执行Spark程序在日志数据中加入会话信息,加入会话信息的规则是在同一IP地址不超过30分钟的两次访问属于一个会话并在日志信息前面加上唯一的会话ID。
5、日志分析人员通过Hue提供的浏览器页面运行已经定制好的查询得到日志分析数据。
4.2 实时异常检测
实时异常检测是指通过发现异常行为和正常行为之间的差异,并及时(比如在几分钟内)采取相应的行动。实时异常检测的一个应用场景是发现异常信用卡交易。比如,一次信用卡交易的金额远大于用户每天的正常交易额,或者本次信用卡交易产生的地理位置不属于该信用卡交易发生的最近20个地方,或者发现通过网上银行发生的本次信用卡交易的IP地址和以前访问的20个不同,均可把该交易标识为异常交易,并采取响应的动作,比如通知客服人员通过电话和信用卡用户进行交易确认,避免信用卡用户或者银行损失。实时异常检测除了用于检测金融欺诈行为外,还可以用于电商网站实时推荐等场景。
以银行信用卡异常检测为例,整个软件架构应满足如下需求:
1、能根据信用卡画像信息(比如信用卡固定信息、累计交易信息,近20次交易历史记录等)和异常检测规则,快速标识异常交易事件。
2、能根据不断产生的信用卡交易事件实时更新信用卡画像信息。
3、能对大量交易日志进行事后分析,不断完善用户画像信息和异常检测规则模型。
基于上述模型,设计如下信用卡交易异常检测软件架构。
大数据实时异常检测软件架构图
在上述架构中,采用HBase来存储上亿条信用卡画像信息,并提供快速查询和更新功能。而通过Kafka,可以把交易事件数据及时注入到HDFS,并通过Spark Steam进行实时分析并更新存储在HBase中的信用卡画像信息。整个实现流程如下:
1、用户信用卡刷卡交易信息发送给交易处理服务器。
2、交易处理服务器会首先从本地缓存中获得信用卡画像信息,或则从HBase中获得最新的用户画像信息。
3、在交易服务器本次对交易异常检测进行判断,并把结果实时更新到HBase。
4、交易事件信息发送到Kafka消息队列。
5、Kafka Topic处理程序会实时把交易事件信息发送到HDFS。
6、基于Spark Stream的实时处理程序会从HDFS中获得交易事件信息并进行关联分析。
7、基于Spakr Steam的实时处理程序把分析结果写入HBase。
8、数据分析人员通过浏览器访问Hue,运行Hive分析脚本或者运行基于Spark机器学习库MLlib的机器学习程序,对交易数据进行分析,并批量更新HBase中的数据。
4.3 企业数据仓库
在大数据时代,企业通常会在Hadoop HDFS存储非结构化数据,而在关系数据中存储结构化数据,这就要求对这两类数据进行整合,并通过各种分析手段发掘数据价值。采用传统的数据仓库技术来整合Hadoop HDFS中的数据,完成数据的整个ETL(抽取Etract、转换Tansform和加载Load)过程,会极大增加数据仓库资金投入成本,也很难完成PB级的非结构化数据处理。因此,基于Hadoop构建企业数据仓库,在Hadoop中完成结构化数据和非结构化数据的ETL过程,利用Hive、Hue等工具进行全面分析,或者在数据抽取和转换形成后,把经过转换的数据导入到企业现有数据仓库,利用各种商业智能(Business Intelligence,简称BI)工具进行数据分析。基于这个思路,采用Hadoop建设数据仓库系统的设计架构如下图:
基于Hadoop的企业数据仓库架构
基于上述架构的企业数据仓库系统的实现逻辑如下:
1、利用Sqoop从关系数据库中抽取结构化数据导入到HDFS。
2、利用Flume或者Kafka把非结构化数据导入到HDFS。
3、优化HDFS中的数据存储模式,包括优化数据模型和文件格式。
4、利用Hive或者Spark对数据进行转换处理。
5、通过Oozie编排整个处理过程,实现ETL过程自动化。
6、利用Hue对变形后数据进行可视化分析。
7、或者通过Sqoop把变形后数据导入到现有数据仓库,利用BI工具进行分析。
5 总结
金山云经过多年公有云运营,已建立强大的IaaS基础设施并积累丰富的运营经验,并提供灵活的云上大数据平台建设方案,帮助企业快速挖掘数据价值,助力企业实现数据驱动业务快速转型。
6 参考资料
1、金山云托管Hadoop KMR服务:http://www.ksyun.com/proservice/kmr
2、金山云云物理主机 EPC服务:http://www.ksyun.com/proservice/physicalmaster
3、金山云云服务器 KEC服务:http://www.ksyun.com/proservice/cloudserver
责任编辑:刘沙




