
Hadoop集群部署(一)——Hadoop基础环境搭建
作者:栾明 | 来源:金山云
2018-06-12
本文在金山云平台上,利用金山云主机及丰富的网络产品和环境,搭建了一套简单的Hadoop的HDFS集群,来实践Hadoop大数据平台的搭建,了解大数据的运行环境和流程,对大数据的知识做一次系统的梳理。
随着国内云计算与大数据产业迅速蓬勃的发展,IT环境的搭建越来越方便,云平台及大数据服务的使用成本却迅速下降,平台的灵活性和扩展性得到了极大程度的提高;不管是大型企业或是个人用户,都可以在很短的时间内在云服务商的平台上搭建出满足自己需求的大数据平台环境,甚至是利用云服务商提供的大数据PAAS产品,一键部署出大数据平台,比如金山云的KMR系列产品。
本文在金山云平台上,利用金山云主机及丰富的网络产品和环境,搭建了一套简单的Hadoop的HDFS集群,来实践Hadoop大数据平台的搭建,了解大数据的运行环境和流程,对大数据的知识做一次系统的梳理。后期会部署更复杂的大数据平台,并做相应的数据清洗、数据挖掘、数据展示等内容。
一、 平台及工具
1.1 Hadoop集群架构
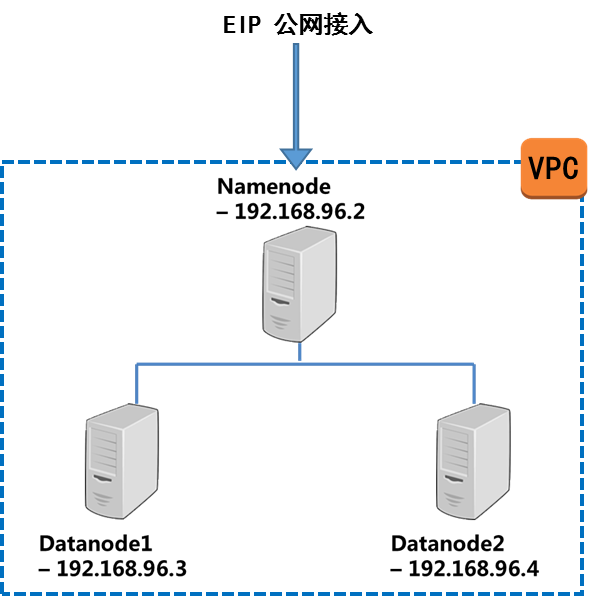
架构上主要部署了1台namenode用作管理者节点(KEC4核4G),2台datanode用作生产者节点(KEC4核4G);3台节点部署在一个VPC及子网内,保证互相之间的通讯并保证基本的安全;节点之间通过ssh通讯,传输相关数据,同时保证传输数据的安全性。外部通讯采用金山云EIP连接到公网。
1.2 Hadoop物理集群搭建
在金山云平台上首先创建一个虚拟私有网络VPC_4 Hadoop(网段192.168.96.0/21);
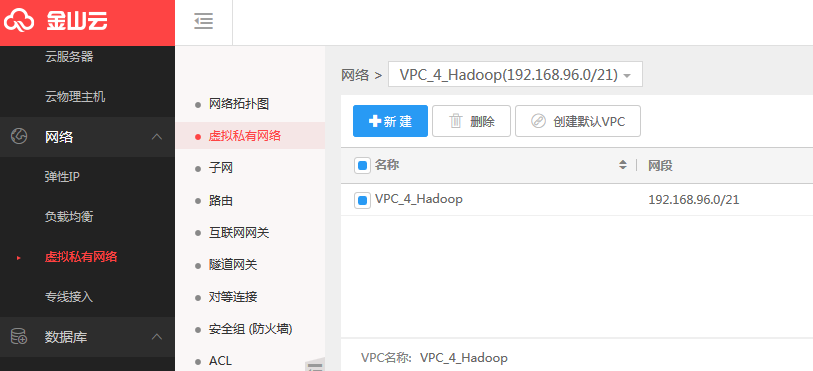
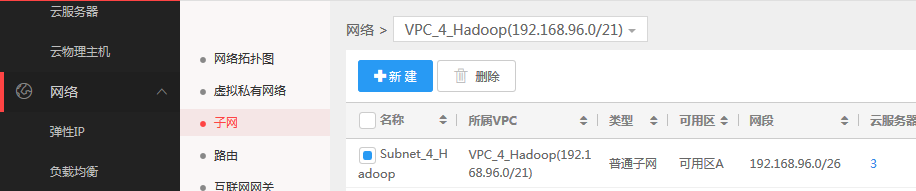
在此VPC下配置好一个子网Subnet4 _hadoop(网段192.168.96.0/26);
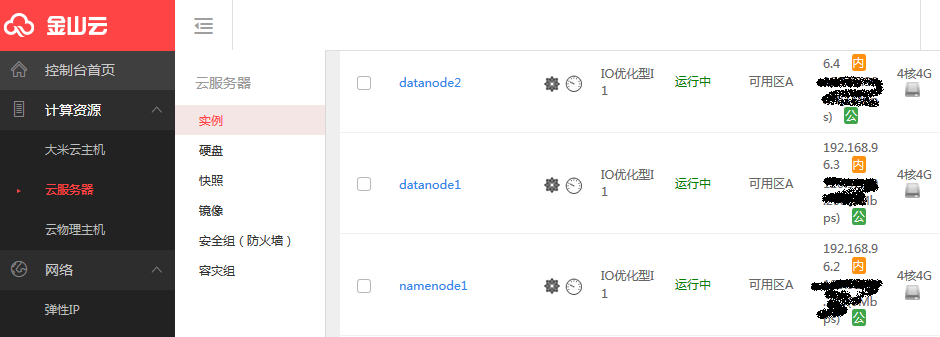
创建3台4vCPU 、4G内存的云主机,部署系统为CentOS7.0,其中一台作为HDFS的管理节点命名为namenode1,另两台作为生产节点分别命名为datanode1、datanode2,并配置在上面创建好的虚拟私有网络及相应的子网中;由于集群规模非常小,为了管理简便为每台虚机都配置了公网地址,更好的管理方法是只为一台云主机配置公网地址作为管理机,通过此台管理云主机管理其他的云主机;
创建好以上资源后,HDFS集群的基本架构就搭建好了,下一步需要在机器上部署Hadoop相关环境。
二、 Hadoop基础环境部署
由于Hadoop是由Java语言编写的,所以必须部署JDK(不知道只部署JRE环境可否);同时Hadoop是处理日志语言的,这方面Perl语言有很强的日志处理能力,可以利用Perl编写Hadoop脚本,最好也部署Perl环境;最后各节点之间需要通讯,所以也需要配置各节点SSH的公钥、私钥,保证通讯的安全性。
2.1 JDK安装
JDK的安装有多种方法,这里使用yum命令安装的方式:
1、首先SSH登录到节点上;
2、利用#yum –y list java*命令查看java安装包有哪些;
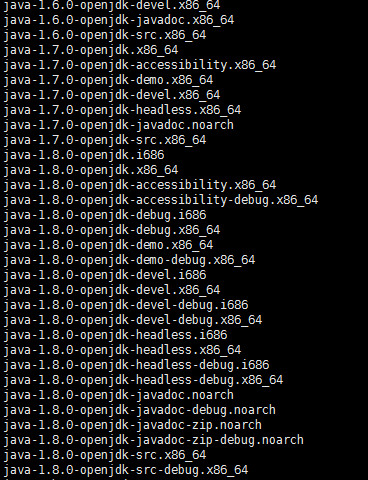
显示主要有1.6.0、1.7.0、1.8.0三个版本;我们决定安装最新的1.8.0版本;
3、利用#yum -y install java-1.8.0-openjdk命令安装JDK1.8.0环境;
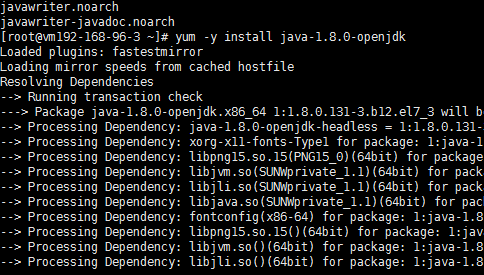
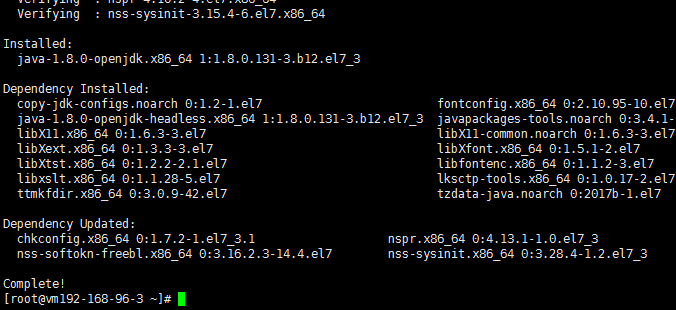
显示Complete!表示安装成功。
4、设置JDK的环境变量;
首先查看JDK默认安装路径一般为/usr/lib/jvm目录下,需要查看文件的全名,我的目录文件名是java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86 _64,这个路径既是java的工作路径;
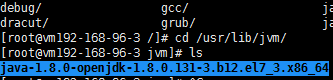
利用#java -version查询java的版本;

利用#vi /etc/profile命令编辑环境变量文件,将Java的执行路径添加到系统路径中; 在文件中添加如下内容:
JAVAHOME=/usr/java/java-1.8.0-openjdk-1.8.0.131-3.b12.el7 _3.x86 64
JREHOME=/usr/java/java-1.8.0-openjdk-1.8.0.131-3.b12.el7 _3.x86 64/jre
PATH=$PATH:$JAVAHOME/bin:$JREHOME/bin
CLASSPATH=:$JAVAHOME/lib/dt.jar:$JAVAHOME/lib/tools.jar:$JREHOME/lib
export JAVAHOME JRE _HOME PATH CLASSPATH
利用#source /etc/profile使修改生效;

利用#echo $path查看路径;

可以看到Java的环境变量已经添加到系统路径中; 到此为止JDK工具已经成功安装;
2.2 jsp的安装
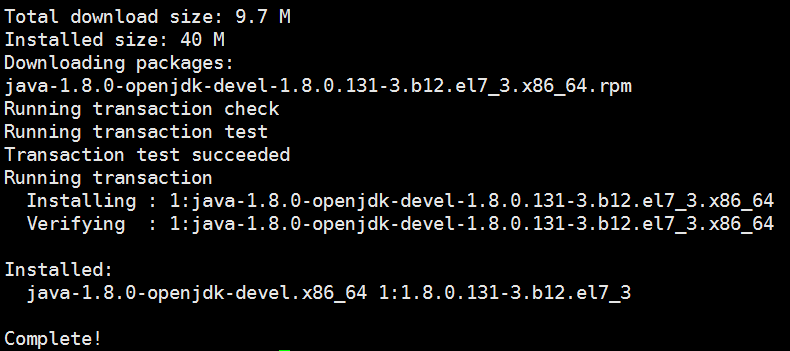
由于我们安装的是openjdk1.8,包中并没有jsp工具,故需要利用yum -y install java-1.8.0-openjdk-devel.x86_64命令安装jsp工具;
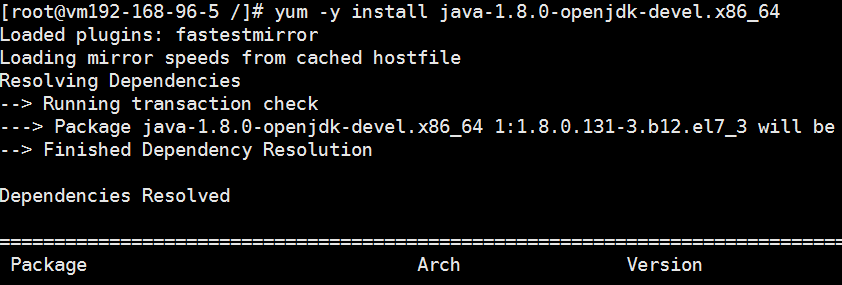
显示如下结果,jsp工具安装成功:
2.3 Perl安装
利用#yum –y install perl* 安装perl的大部分功能; 利用#yum –y install cpan安装CPAN; 利用#perl –v查看perl版本;
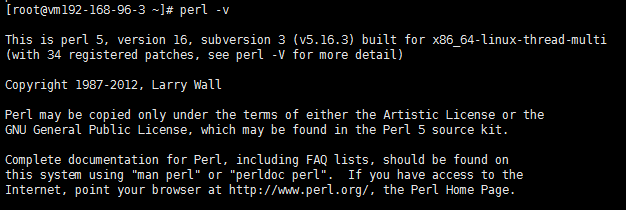
出现如上信息,表示perl已经安装完毕; 这里利用#yum install perl* 安装perl是因为我们利用的Perl模块比较少,如果需要更多模块儿,可以直接从官网下载,在本地安装Perl;
2.4 SSH配置
1、在Linux系统中建立一个新的用户,并设置密码:
useradd '$$$$'(其中$$$$替换成自己的内容)
passwd '$$$$'
2、切换到改用户:
su - '$$$$'
3、生成通讯密钥:
ssh-keygen
4、在3个节点上都生成公钥,并将公钥的文件内容复制到同一个文件authorized _keys中:
cp (本机公钥名) authorized _keys
5、在每台节点上利用这个“公共的”公钥文件替换原先公钥文件,之后即可形成3个节点间的加密通讯;
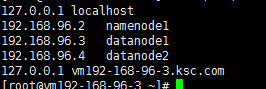
2.5 配置hosts文件
为方便节点间的通讯我们在/etc/hosts文件中,加入如下内容: 192.168.96.2 namenode1
192.168.96.3 datanode1
192.168.96.4 datanode2
通过以上步骤后,Hadoop的基本物理架构及环境已经搭建完毕,接下来就可以在节点上部署Hadoop相关软件了。
本文在金山云平台上,利用金山云主机及丰富的网络产品和环境,搭建了一套简单的Hadoop的HDFS集群,来实践Hadoop大数据平台的搭建,了解大数据的运行环境和流程,对大数据的知识做一次系统的梳理。后期会部署更复杂的大数据平台,并做相应的数据清洗、数据挖掘、数据展示等内容。
一、 平台及工具
1.1 Hadoop集群架构
架构上主要部署了1台namenode用作管理者节点(KEC4核4G),2台datanode用作生产者节点(KEC4核4G);3台节点部署在一个VPC及子网内,保证互相之间的通讯并保证基本的安全;节点之间通过ssh通讯,传输相关数据,同时保证传输数据的安全性。外部通讯采用金山云EIP连接到公网。
1.2 Hadoop物理集群搭建
在金山云平台上首先创建一个虚拟私有网络VPC_4 Hadoop(网段192.168.96.0/21);
在此VPC下配置好一个子网Subnet4 _hadoop(网段192.168.96.0/26);
创建3台4vCPU 、4G内存的云主机,部署系统为CentOS7.0,其中一台作为HDFS的管理节点命名为namenode1,另两台作为生产节点分别命名为datanode1、datanode2,并配置在上面创建好的虚拟私有网络及相应的子网中;由于集群规模非常小,为了管理简便为每台虚机都配置了公网地址,更好的管理方法是只为一台云主机配置公网地址作为管理机,通过此台管理云主机管理其他的云主机;
创建好以上资源后,HDFS集群的基本架构就搭建好了,下一步需要在机器上部署Hadoop相关环境。
二、 Hadoop基础环境部署
由于Hadoop是由Java语言编写的,所以必须部署JDK(不知道只部署JRE环境可否);同时Hadoop是处理日志语言的,这方面Perl语言有很强的日志处理能力,可以利用Perl编写Hadoop脚本,最好也部署Perl环境;最后各节点之间需要通讯,所以也需要配置各节点SSH的公钥、私钥,保证通讯的安全性。
2.1 JDK安装
JDK的安装有多种方法,这里使用yum命令安装的方式:
1、首先SSH登录到节点上;
2、利用#yum –y list java*命令查看java安装包有哪些;
显示主要有1.6.0、1.7.0、1.8.0三个版本;我们决定安装最新的1.8.0版本;
3、利用#yum -y install java-1.8.0-openjdk命令安装JDK1.8.0环境;
显示Complete!表示安装成功。
4、设置JDK的环境变量;
首先查看JDK默认安装路径一般为/usr/lib/jvm目录下,需要查看文件的全名,我的目录文件名是java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86 _64,这个路径既是java的工作路径;
利用#java -version查询java的版本;
利用#vi /etc/profile命令编辑环境变量文件,将Java的执行路径添加到系统路径中; 在文件中添加如下内容:
JAVAHOME=/usr/java/java-1.8.0-openjdk-1.8.0.131-3.b12.el7 _3.x86 64
JREHOME=/usr/java/java-1.8.0-openjdk-1.8.0.131-3.b12.el7 _3.x86 64/jre
PATH=$PATH:$JAVAHOME/bin:$JREHOME/bin
CLASSPATH=:$JAVAHOME/lib/dt.jar:$JAVAHOME/lib/tools.jar:$JREHOME/lib
export JAVAHOME JRE _HOME PATH CLASSPATH
利用#source /etc/profile使修改生效;
利用#echo $path查看路径;
可以看到Java的环境变量已经添加到系统路径中; 到此为止JDK工具已经成功安装;
2.2 jsp的安装
由于我们安装的是openjdk1.8,包中并没有jsp工具,故需要利用yum -y install java-1.8.0-openjdk-devel.x86_64命令安装jsp工具;
显示如下结果,jsp工具安装成功:
2.3 Perl安装
利用#yum –y install perl* 安装perl的大部分功能; 利用#yum –y install cpan安装CPAN; 利用#perl –v查看perl版本;
出现如上信息,表示perl已经安装完毕; 这里利用#yum install perl* 安装perl是因为我们利用的Perl模块比较少,如果需要更多模块儿,可以直接从官网下载,在本地安装Perl;
2.4 SSH配置
1、在Linux系统中建立一个新的用户,并设置密码:
useradd '$$$$'(其中$$$$替换成自己的内容)
passwd '$$$$'
2、切换到改用户:
su - '$$$$'
3、生成通讯密钥:
ssh-keygen
4、在3个节点上都生成公钥,并将公钥的文件内容复制到同一个文件authorized _keys中:
cp (本机公钥名) authorized _keys
5、在每台节点上利用这个“公共的”公钥文件替换原先公钥文件,之后即可形成3个节点间的加密通讯;
2.5 配置hosts文件
为方便节点间的通讯我们在/etc/hosts文件中,加入如下内容: 192.168.96.2 namenode1
192.168.96.3 datanode1
192.168.96.4 datanode2
通过以上步骤后,Hadoop的基本物理架构及环境已经搭建完毕,接下来就可以在节点上部署Hadoop相关软件了。
责任编辑:刘沙




