

1.2毫秒!英伟达TensorRT 8运行BERT-Large推理创纪录
7月20日,NVIDIA发布了第八代AI软件TensorRT 8。英伟达AI软件部产品管理总监 Kari Briski、产品营销主管 Siddharth Sharma就TensorRT 8的技术细节、应用落地等相关情况进行了介绍。
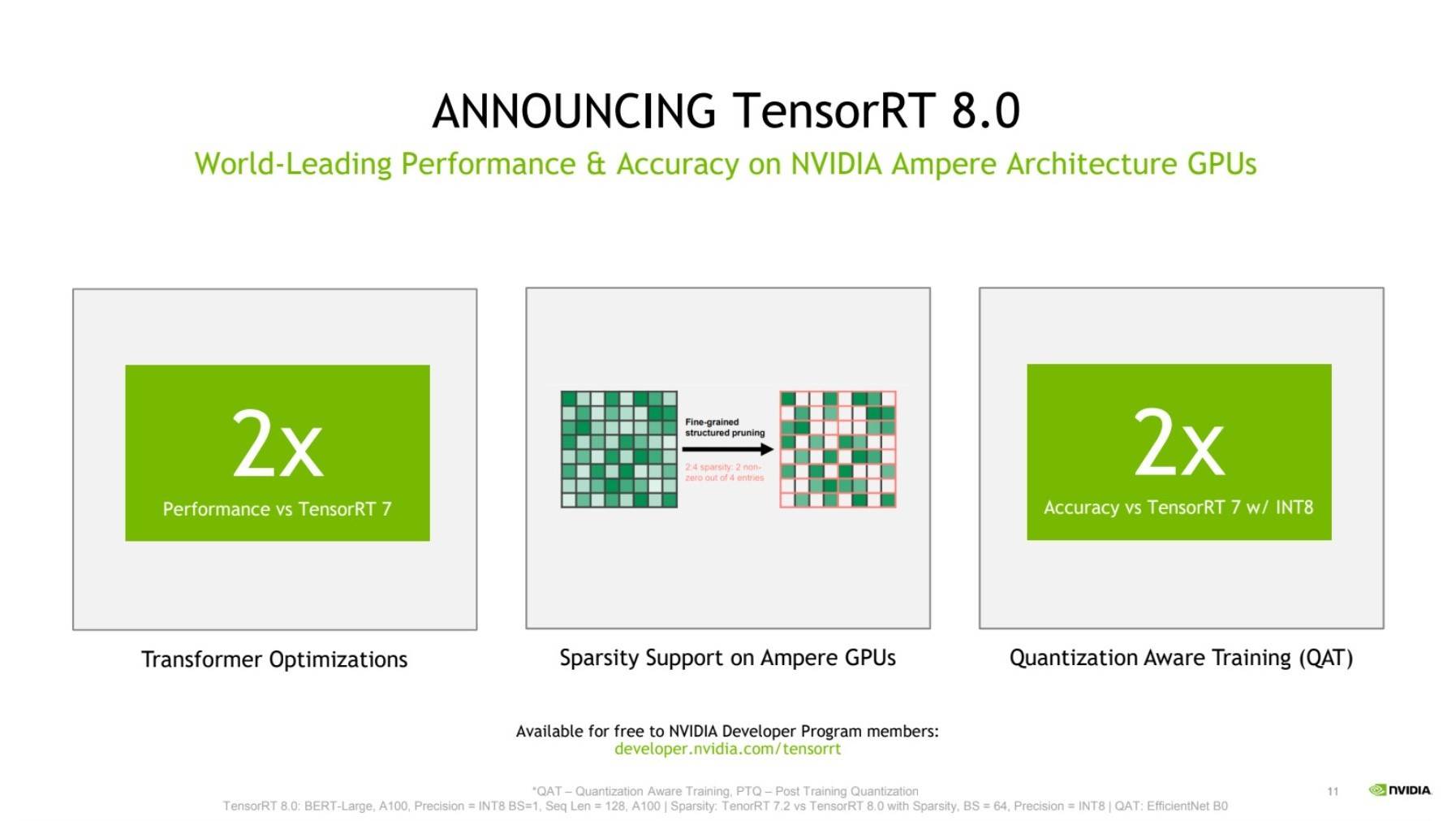
据悉,TensorRT 8将语言查询推理时间缩短了一半,使开发者能够从云端到边缘构建全球最佳性能的搜索引擎、广告推荐和聊天机器人。
语言应用再加速
通过TensorRT,开发者可将TensorFlow、Pytorch等训练好的框架模型进行优化,从而推动其在英伟达GPU上的运行。2019年,英伟达发布TensorRT 7,为智能的AI人际交互打开了大门,实现了与语音代理、聊天机器人和推荐引擎等应用的实时互动。
而此次发布的TensorRT 8再次进行了各项优化,为语言应用带来了创纪录的速度。TensorRT 7配合A100 GPU可实现在2.5毫秒内运行BERT-Large,此次新发布的TensorRT 8将时间缩减至了1.2毫秒。过去,企业不得不缩减模型大小,导致结果出现大幅偏差。现在有了TensorRT 8,企业可以将其模型扩大一倍或两倍,从而大幅提高精度。
NVIDIA开发者计划副总裁Greg Estes表示:“AI模型正以指数级的速度增长。全世界对AI实时应用的使用需求正在激增。这使企业必须部署最先进的推理解决方案。最新版本的TensorRT引入了多项新功能,使企业能够以前所未有的质量和响应速度向其客户提供对话式AI应用。”
据介绍,TensorRT可部署于超大规模的数据中心、嵌入式或汽车产品平台。五年来,医疗、汽车、金融和零售等各个领域27,500家企业的超35万名开发者下载TensorRT近250万次。
AI推理新突破
TensorRT是英伟达推出的深度学习推理框架,在模型推理的过程中,可以将Pytorch、TensorFlow等其他框架训练好的模型转化为TensorRT格式,再使用TensorRT推理引擎运行,从而提升这一模型在GPU上的运行速度。
因此,支持更多的模型和进一步缩短推理时间,提高推理速度是广大AI软件开发者对TensorRT升级的普遍期望。
TensorRT 8除了针对transformer的优化之外,还通过其他两项关键特性,实现了AI推理方面的突破。
首先是稀疏性,这是助力推动NVIDIA Ampere架构GPU性能提升的一项全新技术,它不但提高了效率,还使开发者能够通过减少计算操作来加速其神经网络。
其二是量化感知训练,开发者能够使用训练好的模型,以INT8精度运行推理,在这一过程中不会损失精度。大大减少了计算和存储成本,从而在Tensor Core核心上实现高效推理。
多行业应用
TensorRT目前已经应用于多个行业的对话式AI和其他各领域的深度学习推理中。
据介绍, Hugging Face正与NVIDIA开展密切合作,推出能够助力实现大规模文本分析、神经搜索和对话式应用的开创性AI服务。
Hugging Face产品总监Jeff Boudier表示:“我们正在与NVIDIA开展密切合作,以基于NVIDIA GPU,为最先进的模型提供最佳性能。Hugging Face加速推理API已经能够为基于NVIDIA GPU的transformer模型提供高达100倍的速度提升。通过TensorRT 8,Hugging Face在BERT上实现了1毫秒的推理延迟。”
此外,医疗技术、诊断和数字解决方案创新者GE医疗也表示在使用TensorRT助力加速早期检测疾病工具“超声波计算机视觉”的应用,使临床医生能够通过其智能医疗解决方案提供最高质量的护理。
GE医疗心血管超声首席工程师Erik Steen表示:“临床医生需要花费宝贵的时间来选择和评估超声图像。在Vivid Patient Care Elevated Release项目的研发过程中,我们希望通过在Vivid E95扫描仪上实施自动心脏视图检测,使这一过程变得更加高效。心脏视图识别算法将选择合适的图像来分析心壁运动。TensorRT凭借其实时推理能力,提高了视图检测算法的性能,同时缩短了我们研发项目的产品上市时间。”
责任编辑:王莉娟




